How to manage a quantum computing emergency
You go to war with the algorithms you have, not the ones you wish you had
Posted by ekr on 16 Apr 2024

Recently, I wrote about how the Internet community is working towards post-quantum algorithms in case someone develops a cryptographically relevant quantum computer (CRQC). That's still what everyone is hoping for, but nobody really know when or even if a CRQC is developed, and even in the best case the transition is going to take a really long time, so what happens if someone builds a CRQC well in advance of when that transition is complete? Clearly, this takes the situation that is somewhere between non-urgent and urgent to one that is outright emergent but that doesn't mean that all is lost. In this post, I want to look at what we would do if a CRQC were to appear sooner rather than later. As with the previous post, this post primarily focuses on TLS and the Web, though I do touch on some other protocols.
Obviously there are a lot of scenarios to consider and "cryptographically relevant" is doing a lot of work here. For instance, we typically assume that the strength of X25519 is approximately 2128 bits. A technique which brought the strength down to 280 would be a pretty big improvement as an attack and would definitely be "cryptographically relevant" but would also still leave attack quite expensive; it probably wouldn't be worth using this kind of CRQC to attack connections carrying people's credit cards, especially if each connection had to be attacked individually, at a cost of 280 operations each time. This would obviously be a strong incentive to accelerate the PQ transition, but probably wouldn't be an outright emergency unless you had particularly high value communications.
For the purpose of this post, let's assume that:
-
This is a particularly severe attack, bringing the existing algorithms within range of commercial attackers in a plausible time frame, whether that's days or real time.[1]
-
It happens at some point in the next few years, while there is significant deployment but by no means universal deployment of PQ key establishment and minimal if any deployment of PQ signatures and certificates.
This is close to a worst-case scenario in that our existing
cryptography is severely weakened but it's not practical to just
disable it and switch to PQ algorithms. In other words isn't it's
an emergency and we leaves us with a fairly limited set of options.
[Corrected, 2024-04-15]
Key Establishment #
The first order of business is to do something about key establishment. Obviously if you haven't already implemented a PQ-hybrid or pure PQ algorithm, you'll want to do that ASAP, selecting whichever one is more widely deployed (or potentially doing both if some peers do one and some the other).
Once you've added support for some PQ algorithm, the question is whether you should disable the classical algorithm. The naive answer is "no": even if the classical algorithm severely weakened, any encryption is better than no encryption. In reality, the situation is a bit more complicated.
Recall that in TLS, the client proposes a set of algorithms and the server selects one, as shown below:
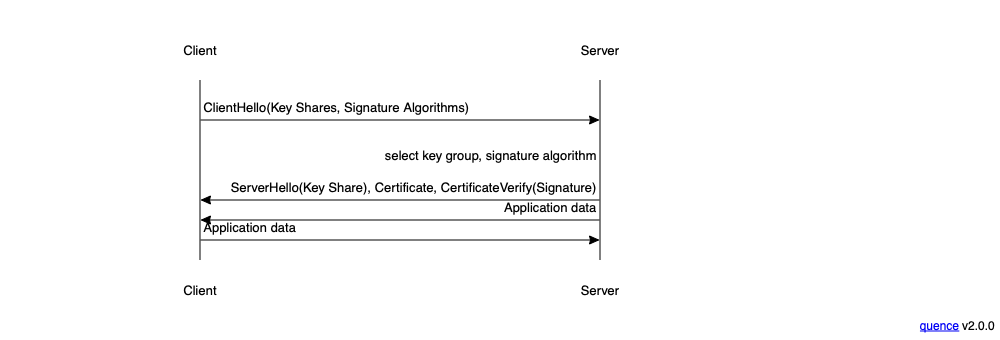
The idea here is that the server gets to see what algorithms the client supports and pick the best algorithm. As long as the client and server agree on the algorithm ranking, then this will generally work fine. However, it's possible that the servers and clients will disagree, in which case the server's preferences will win.[2]
This actually happened during the transition away from the RC4 symmetric cipher. After a series of papers showed significant weaknesses in RC4, the browsers decided they preferred AES-GCM. Unfortunately, many servers preferred RC4, and so the result was that even when both clients and servers supported RC4 and AES-GCM, many servers selected RC4. In response, browsers (starting with IE[3] adopted a system in which they first tried to connect without offering RC4, and if that failed they then retried with it, as shown below:
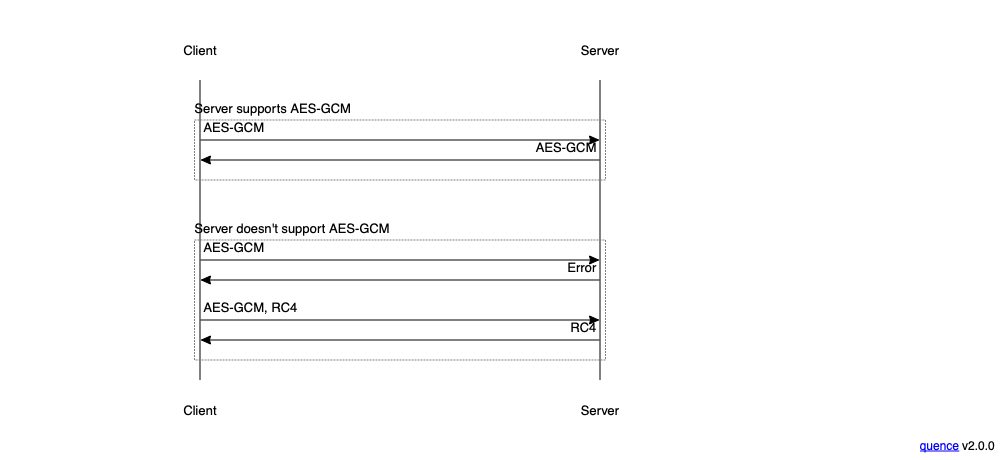
The result was that any server which supported AES-GCM would negotiate it, but if the server only supported RC4, the client could still connect. This also made it possible to measure the fraction of servers which supported AES-GCM, thus providing information about about how practical it was to disable RC4.
Downgrade Attacks #
So far we've only considered a passive attacker, but what about an active attacker? TLS 1.3 is designed so that the signature from the server protects the handshake, so as long as the weakest signature algorithm supported by the client is strong, an active attacker can't tamper with the results of the negotiation.[4] The fallback system described above weakens this guarantee a little bit in that the attacker can forge an error and force the client into the fallback handshake. However, the client will still offer both algorithms in the fallback handshake, so the attacker can't stop the server from picking its preferred algorithm; it can just stop the client from getting the client's preferred algorithm by manipulating the first handshake.
Of course, if the server's signature isn't strong—or more properly the weakest signature algorithm the client will accept isn't strong—then the the attacker can tamper with the negotiated key establishment algorithm. However, an attacker who can do that can just impersonate the server directly, so it doesn't matter what key establishment algorithms the client supports.
Maybe it's better to fail open #
The bottom line here is that as long as you're not under active attack, TLS will deliver the strongest[5] algorithm that's jointly supported by the peers, and, if you're under active attack by an attacker who can break signature algorithms, then all bets are off. That's probably the best you can do if you're determined to connect to the server anyway. But the alternative is, don't connect.
The basic question here is how sensitive the communication with the site is. If you're just looking up some recipes or reading the news, then it's probably not that big a deal if your connection isn't secure (in fact, people used to regularly argue that it wasn't necessary at all, though that's obviously not a position I agree with). On the other hand, if you're doing your banking or reading your e-mail, you probably really don't want to do that unencrypted. This isn't to say that we don't want ubiquitous encryption—we do—or that it's not possible for even innocuous seeming communications to be sensitive—it is—but to recognize that this scenario would force us to make some hard choices about whether we're willing to communicate insecurely if that's the only option. These are hard choices for a human and even harder for a piece of software like a browser (it's much easier for a standalone mail client, obviously).
This is actually a situation where ubiquitous encryption makes things rather more difficult. Back when encryption was rare, it was a reasonable bet that if a site was encrypted then the operators thought it was particularly sensitive. But now that everything is encrypted, it's much harder to distinguish whether it's really important for this particular connection to be protected versus just that it's good general practice (which, again, it is!).
One thing that may not be immediately obvious is that an insecure connection can threaten not just the data that you are sending over it, but other data as well. For example, if you are reading your email, you're probably authenticating with either a password (with a normal mail client) or a cookie (with Webmail). Both of these are just replayable credentials, so an attacker who can decrypt your connection can impersonate you to the server and download all your email, not just the messages you are reading now As discussed above, an attacker who recorded your traffic in the past might still be able to recover your password, but this is a lot more work than just getting it off the wire in real time.
Signature Algorithms #
Of course, none of this does anything to authenticate the server,
which is critical for protecting against active attack. For that we
need the server to have a certificate with a PQ algorithm and the
client to refuse to trust certificates that either (1) are signed with
a classical algorithm or (2) contain keys for a classical
algorithm. Importantly, it's not enough for the server to stop using a
PQ classical [Fixed 2024-04-15] certificate, because the server doesn't have to be part of the
connection at all. In fact, even if the server doesn't have a PQ
certificate, attack is still possible because the attacker can just
forge the entire certificate chain.
As described in my previous post, the first thing that has to happen is that servers have to deploy PQ certificates. Without that, there's not much the clients can do to defend themselves. In this case, I would expect there to be a huge amount of pressure to do that ASAP, despite the serious size overhead issues with PQ certificates noted by Bas Westerban and David Adrian. After all, it's better to have a slow web site than one that's not secure or that people can't connect to.
For the same reason, I would expect there to be a lot less concern about the availability of hardware security modules (HSMs) for the new PQ algorithms or whether the algorithms in question have gone through the entire IETF standards process [Added link 2024-04-15]. Those are both good things, but having PQ safe certificates is more important, so I would expect the industry to converge pretty fast on a way forward.
Once there is some level of PQ deployment, clients can start distrusting the classical algorithms (before that, there's not much point). However, as with key establishment: if the client distrusts classical algorithms than it won't be able to connect to any server that doesn't have a PQ certificate, which will initially be most of them, even in the best case. This is frustrating because it means that you have to choose between failure to connect or having protection against active attack. What you'd really like is to have the best protection you can get, i.e.,
- Only trust PQ algorithms for sites that have PQ certificates (so you aren't subject to active attack).
- Allow classical algorithms for sites without PQ certificates (so you at least get protection against passive attack).
Actually, there are three categories here:
- Sites which are so sensitive that you shouldn't connect to them without a PQ certificate (e.g., your bank).
- Sites which are known to have a PQ certificate and so you shouldn't accept a classical certificate (probably big sites like Google).
- Sites that aren't that sensitive and so you'd be willing to connect to them with a classical certificate (e.g., the newspaper).
The problem is being able to distinguish which category a site falls into. Usually, we don't try to draw this kind of distinction, and just let the site tell us if it wants TLS, but this isn't a usual situation, so it's worth exploring some inconvenient things.
PQ Lock #
The most obvious thing is to have the client remember when the server has a PQ certificate and thereafter refuse to accept a classical certificate. Unfortunately, this idea doesn't work well as-is, because server configurations aren't that stable. For instance:
- A site might roll out PQ and then have problems and disable it.
- A site might have multiple servers and gradually roll out PQ certificates on one of them.
- A site might be served by more than one CDN with different configurations.
Note that in cases (2) and (3) the client will not generally be aware that there are different servers, as they have the same domain name, and IP addresses aren't reliable for this purpose (and, in any case, are likely under control of the attacker because DNS isn't very secure). An in case (1) it's actually the same server.
In any of these situations you could have a situation where the client contacts the server, get a PQ certificate, and then come back and get a classical certificate, so if the client just forbids any use of classical after PQ, this would create a lot of failures. Fortunately, we've been in this situation before with the transition to HTTPS from HTTP, so we know the solution: the server tells the client "from now on, insist on the new thing," and the client remembers that.
With HTTP/HTTPS, this is a header called HTTP Strict Transport Security (HSTS) and has the semantics "just do HTTPS from now on with this domain". It would be straightforward to introduce a new feature that had the semantics "just insist on PQ from now on with this domain". In fact, the HSTS specification is extensible, so if you wanted to also insist on HTTPS (a good idea!), you could probably just add a new directive saying "also require PQ". It would also be easy to add a new HTTP header that said "if you do HTTPS, require PQ", as HTTP is nicely extensible and unknown headers are just ignored.
One of the obvious problems with an HSTS-like header—and in fact with HSTS itself—is that it relies on the client at some point connecting to the server while not under attack. If the attacker is impersonating the server then they just don't send the new header. They can even connect to the real server and send valid data otherwise, but just strip the header. This is still a real improvement, though, as the attacker needs to be much more powerful: if the client is ever able to form a secure connection to the true server, then it will remember that PQ is needed and be protected against attack from then on, even if it's not protected from the beginning.
Preloading #
It's possible to protect the user from active attack from the very beginning by having the client software know in advance which servers support PQ. There is already something that browsers do with HSTS, where it's called "HSTS preloading". Chrome operates a site where server operators can request that their sites be added to the "HSTS preload list". The site does some checking to make sure that the server is properly configured and then Chrome adds it to their list. In principle, other browsers could do this themselves, but in practice, I think they all start from Chrome's list.
In principle, we could use a system like this for PQ preloading as well, but there are scaling issues. The HSTS preload list is fairly sizable (~160K entries as of this writing), but this only represents a small fraction of the domains on the Internet. For example, Let's Encrypt is currently issuing certificates for more than 100 million registered domains and over 400 million fully qualified domains. If we assume that sites which have moved to PQ are aggressive about preloading—which they should be for security reasons—we could be talking about 10s of millions of entries. The current Firefox download is about 134 MB, so we're probably looking at a nontrivial expansion in the size of a browser download to carry the entire preload list, even with compact data structures. On the other hand, it's probably not totally prohibitive, especially in the early years when there is likely to not be that much preloading.
There may also be ways to avoid downloading the entire database. For instance, you could use a system like Safe Browsing which combines an imperfect summary data structure with a query mechanism, so that you can get offline answers for most sites, but then will need to check with the server to be sure. The Safe Browsing database has about 4 million entries—or at least did back in 2022—so you probably could repurpose SB-style techniques for something like this, at least until PQ certificates got a lot more popular.[6] The privacy properties of SB-style systems aren't as good as just preloading the entire list, so there's a tradeoff here, so it would be a matter of figuring out the best of a set of not-great options.
Of course, browser vendors don't need to wait for servers to ask to be preloaded; they could just add them proactively, for instance by scanning to see which sites advertise the PQ-only header, or even which sites just support PQ algorithms. Obviously there's some risk of prematurely recording a site as PQ-only, but there's also a risk in allowing non-PQ connections in this situation, The higher the proportion of servers that support these algorithms, the more aggressive browser vendors can be about requiring PQ support, and the more readily they can add servers to the list, even if the server hasn't really directly signaled that it wants to be included.
Site Categorization #
There are other indicators that can be used to determine whether a site is especially sensitive and so needs to be reached over a PQ-secure connection or not at all. This could happen both browser side or server side based on a variety of indicia such as requiring a password or being a medical or financial site. One could even imagine building some kind of statistical or machine learning model to determine whether sites were sensitive. This doesn't have to be perfect as long as it's significantly better than static configuration.
Reducing overhead #
Obviously, we would be in a better position if it weren't so expensive to use PQ signature algorithms. Mostly, this is about the size of the signatures. As noted in Bas's post, there are a number of possible options for reducing the size overhead, these include:
- Removing known intermediate and root certificates
- Smart compression of certificates based on a database of known certificates
- Completely reworking the entire structure of certificates.
All of these mechanisms are designed to be be backward compatible, meaning that the client and the server can detect if they both support the optimization and use it, but can fall back to the more traditional mechanisms if not. The first two mechanisms work with existing WebPKI certificates, and would work with PQ certificates as well, requiring only that the client and server software be updated to support the optimization.
The last mechanism ("Merkle tree certificates") replaces existing WebPKI certificates, and so would require servers to get both a PQ WebPKI certificate and a PQ Merkle tree certificate, and conditionally serve the right one depending on the client's capabilities. This is obviously more work for the server operator (the same for the browser user). On the other hand, if server operators are already going to have to change their processes to get both PQ and classical certificates, it would be a convenient time to also change to get a Merkle tree certificate.
HTTP Public Key Pinning #
Obviously, in addition to recording that the server supported PQ algorithms you could remember the server's PQ signature key and insist that the server present that in the future (this is how SSH works). In the past the TLS community explored more flexible versions of this approach with a technique called HTTP Public Key Pinning. HPKP was eventually retired, in part due to concerns about how easy it was to render your site totally unusable by pinning the wrong key and in part because mechanisms like Certificate Transparency seemed to make it less important.
One might imagine resurrecting some variant of HPKP for a PQ transition as a stopgap during a period where sites are prepared to deploy PQ but CAs can't issue them yet. This wouldn't be quite the same because the server would have to authenticate with its classical certificate but then pin the PQ key, which would be accepted without a certificate chain, which HPKP doesn't support. My sense is that we could probably manage to get some issuance of PQ certificates faster than we could design a new HPKP type mechanism and get it widely deployed, but it's probably still an option worth remembering in case we need it.
What about TLS 1.2? #
One challenge with the story I told above is that PQ support is only available in TLS 1.3, not TLS 1.2.[7] This means that anyone who wants to add PQ support will also have to upgrade to TLS 1.3. On the one hand, people will obviously have to upgrade anyway to add the PQ algorithms, so what's the big deal. On the other hand, upgrading more stuff is always harder than upgrading less. After all, the TLS working group could define new PQ cipher suites for TLS 1.2, and it's an emergency so why not just let use people use TLS 1.2 with PQ rather than trying to force people to move to TLS 1.3. On the gripping hand, TLS 1.3 is very nearly a drop-in replacement for TLS 1.2. There is one TLS 1.2 use case that it TLS 1.3 didn't cover (by design), namely the ability to passively decrypt connections if you have the server's private key (sometimes called "visibility"), which is used for server side monitoring in some networks. However, this technique won't work with PQ key establishment either, so it's not a regression if you convert to TLS 1.3.
Non-TLS systems #
Much of what I've written above applies just as well to many other interactive security protocols such as IPsec or SSH,[8] which are designed along essentially the same pattern. Any non-Web interactive protocol is likely to have an easier time because there will be a fairly limited number of endpoints you need to connect to, so you can more readily determine whether the other side has upgraded or not. As a concrete example, SSH depends on manual configuration of the keys (the server's key is usually done on a "trust on first use" basis when the client initially connects). Once that setup is done, you don't need to discover the peer's capabilities. By contrast, a Web browser has to be able to connect to any server, including ones it has no prior information about.
There is a huge variety of other cryptographic protocols and our ability to recover from a CRQC would vary a lot. Especially impacted will be anything which relies on long-term digital signatures, as they are hard to replace. A good example here is cryptocurrency systems like Bitcoin which rely on signatures to effect the transfer of tokens: if I can forge a signature from you then I can steal your money. The right defense against this is to replace your classical key with a PQ key (effectively to transfer money to yourself), but we can assume that a lot of people won't do that in time, and as soon as a CRQC is available, any future transaction becomes questionable.
The situation around Bitcoin seems to actually be pretty interesting. The modern way to do Bitcoin transfers is to transfer them not to a public key but the hash of a public key (called pay to public key hash (p2pkh)). As long as the public key isn't revealed, then you can't use a quantum computer to forge a signature. The public key has to be revealed in order to transfer the coin, but if you don't reuse the key, then there is only a narrow window of vulnerability between the signature and when the payment is incorporated into the blockchain (which doesn't depend on public key cryptography). However, according to this study by Deloitte, about 25% of Bitcoins are vulnerable to a CRQC, so that's not a great situation.
What if the PQ algorithms aren't secure? #
All of the above assumes that we have public key algorithms that
are in fact secure against both classical and quantum computers.
In that case, our problem is "just" transitioning from our
insecure classical algorithms to their more-or-less interface
compatible PQ replacements. But what happens if those algorithms
turn out to be
secure
insecure [Corrected 2024-04-15]
after all. In that case we are in truly
deep trouble. Obviously the world got on OK for centuries without
public key cryptography, but now we have an enormous ecosystem
based on public key cryptography that would be rendered insecure.
Some of those applications may just get abandoned (maybe we don't really need cryptocurrencies...) but it would obviously be very bad if nobody was able to safely buy anything on Amazon, use Google docs, or that your health care records couldn't be transmitted securely, so there's obviously going to be a lot of incentive to do something. The options are pretty thin, though.
Signature #
We do have at least one signature algorithm which we have reasonably high confidence is secure: hash signatures, which NIST is standardizing as "SLH-DSA". Unfortunately, the performance is extremely bad (we're talking 8KB signatures). On the other hand, slow and big signature algorithms are better than no signature algorithms at all, so there are probably some applications where we'd see some use of SLH-DSA.
Key Establishment #
While the signature story is bad, but the key establishment story is really dire. The main option people seem to be considering is some variant of what I've been calling intergalactic Kerberos. Kerberos is a security protocol designed at MIT back in the 80s and in its original form works by having each endpoint (user, server) share a pairwise symmetric[9] key with a key distribution server (KDC).
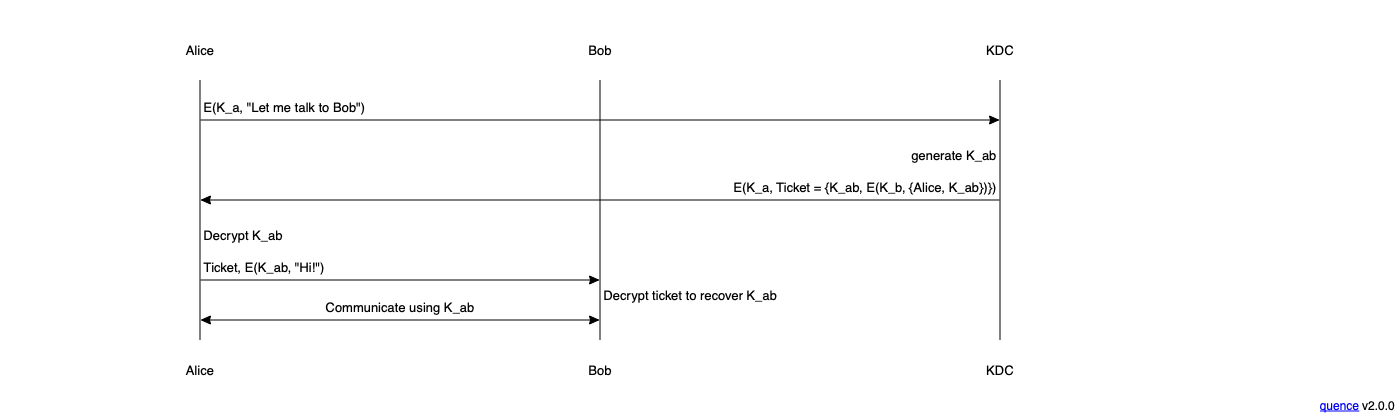
At a high level, when Alice wants to talk to Bob, she contacts the KDC using a message encrypted with her pairwise key K_a and tells it that it wants to contact Bob. The KDC creates a new random key R_ab and then sends Alice two values:
- R_ab
- A copy of R_ab encrypted under Bob's key (K_b), i.e., E(K_b, {Alice, K_ab}). In Kerberos terms this is called a "ticket".
Alice can then contact Bob and present the ticket. Bob decrypts the ticket and recovers K_ab. Now Alice and Bob share a key they can use to communicate. Note that this all uses symmetric cryptography, so it's not vulnerable to attacks on our PQ algorithms. You can wire up this kind of key establishment mechanism into protocols like TLS (TLS 1.2 actually has Kerberos integration, but it wasn't ported into TLS 1.3) and use them in something approximating the usual fashion, albeit in a much clunkier fashion.
Merkle Puzzle Boxes #
It turns out that there actually sort of is a public key system that doesn't depend on any fancy math and so we can have reasonable confidence in how secure it is. In fact, it's the original public key system, invented by Ralph Merkle. This post is already pretty long, so if you're interested check out the Wikipedia page. The TL;DR is that it's probably not that practical because (1) public key sizes are enormous and (2) it only offers the defender a quadratic level of security (if the defender does work N the attacker does work N2 to break it), which isn't anywhere near as good as other algorithms. There seem to be some quantum attacks on puzzle boxes (though I'm not sure how good they are in practice), but there is also a PQ variant.
This kind of design has a number of challenges. First, it's much harder to manage. In a public-key based system clients don't need to have any direct relationship with the CA, because they just need the CA's public key. In a symmetric key system, however, each client needs a relationship with the KDC in order to establish the shared key. This is obviously a huge operational challenge.
The basic challenge with this kind of design is that the KDC is able to decrypt K_ab and hence any traffic between Alice and Bob. This is because the KDC is providing both authentication and key establishment, unlike with a public key system like the WebPKI where the CA provides authentication but the endpoints perform key establishment using asymmetric algorithms. This is just an inherent property of symmetric-only systems, and it's what we're reduced to if we don't have any CRQC-safe asymmetric algorithms.
One potential mitigation is to have multiple KDCs and then Alice and Bob use a key derived from exchanges with those KDCs. In such a system, the attacker would need to compromise all of the KDCs in use for a connection in order to either (1) impersonate one of the endpoints or (2) decrypt traffic. Recently we've started to see some interest in symmetric key type solutions along these lines, including a draft at the IETF and a recent blog post by Adam Langley.[10] My sense is that due to the drawbacks mentions above, this kind of system isn't likely to take off as long as we have PQ algorithms, even if they're not that efficient. However, if the worst happens and we don't have asymmetric PQ algorithms at all, we're going to have to do something, and symmetric-based systems will be one of the options on the table.
The Bigger Picture #
As I mentioned in the previous post, we shouldn't expect the PQ transition to happen very quickly, both because the algorithms aren't all that we'd like and because even with better algorithms the transition is very disruptive. However, because the Internet is so dependent on cryptography and in particular public key cryptography, there would be enormous demand to do something if a CRQC were to be developed any time soon. When compared to the alternative of no secure communications at all, a lot of options that we would have previously considered unattractive or even totally non-viable would suddenly look a lot better, and I would expect the industry to have to make a lot of tough choices to get anything at all to work while we worked out what to do in the long term.
This distinction does matter for some attacks, but even if it's days, the situation is really bad. ↩︎
Unless the server decides to defer to the client, of course. ↩︎
Thanks to David Benjamin for help with the history of this technique. ↩︎
This is a new feature of TLS 1.3. In TLS 1.2, the security of the handshake depended on the weakest common key establishment algorithm, which left it vulnerable to attacks if the weakest algorithm was breakable in real-time. ↩︎
Again with the caveats above about preferences ↩︎
The worst case is when about 1/2 of the sites want to be preloaded; once you get to well over 50%, you can instead publish the list of non-preloaded sites, though this is logistically a bit trickier, as you'd need a list of every site. You can get this list from Certificate Transparency, though, which is what CRLite does. ↩︎
Obviously, there's an element of "we're trying to avoid maintaining TLS 1.2 and we want people to upgrade" going on here, but there's also a small technical advantage here: although TLS 1.2 and TLS 1.3 both authenticate the server by having the server sign something, in TLS 1.2 the signature only covers part of the handshake (specifically, the random nonces and the server's key), which means that the signature doesn't cover the key establishment algorithm negotiation. This means that an attacker who can break the weakest joint key establishment algorithm can mount a downgrade attack, forcing you back to that weakest algorithm. However, we could presumably address this by remembering that both key establishment and authentication are PQ only. ↩︎
Note: QUIC uses the TLS 1.3 handshake under the hood, so it has roughly the same properties as TLS 1.3 ↩︎
Langley's design actually assumes that PQ algorithms work but are too inefficient to use all the time, so you use it to bootstrap the symmetric keys with the KDC. ↩︎